Exponential Loss Machine Learning
In many deep learning literatures both sigmoid and softmax cross entropy loss are called cross entropy loss which can be determined by the problem itself. Something called Deep Learning began emerging in 2012.
10 Empirical Risk Minimization
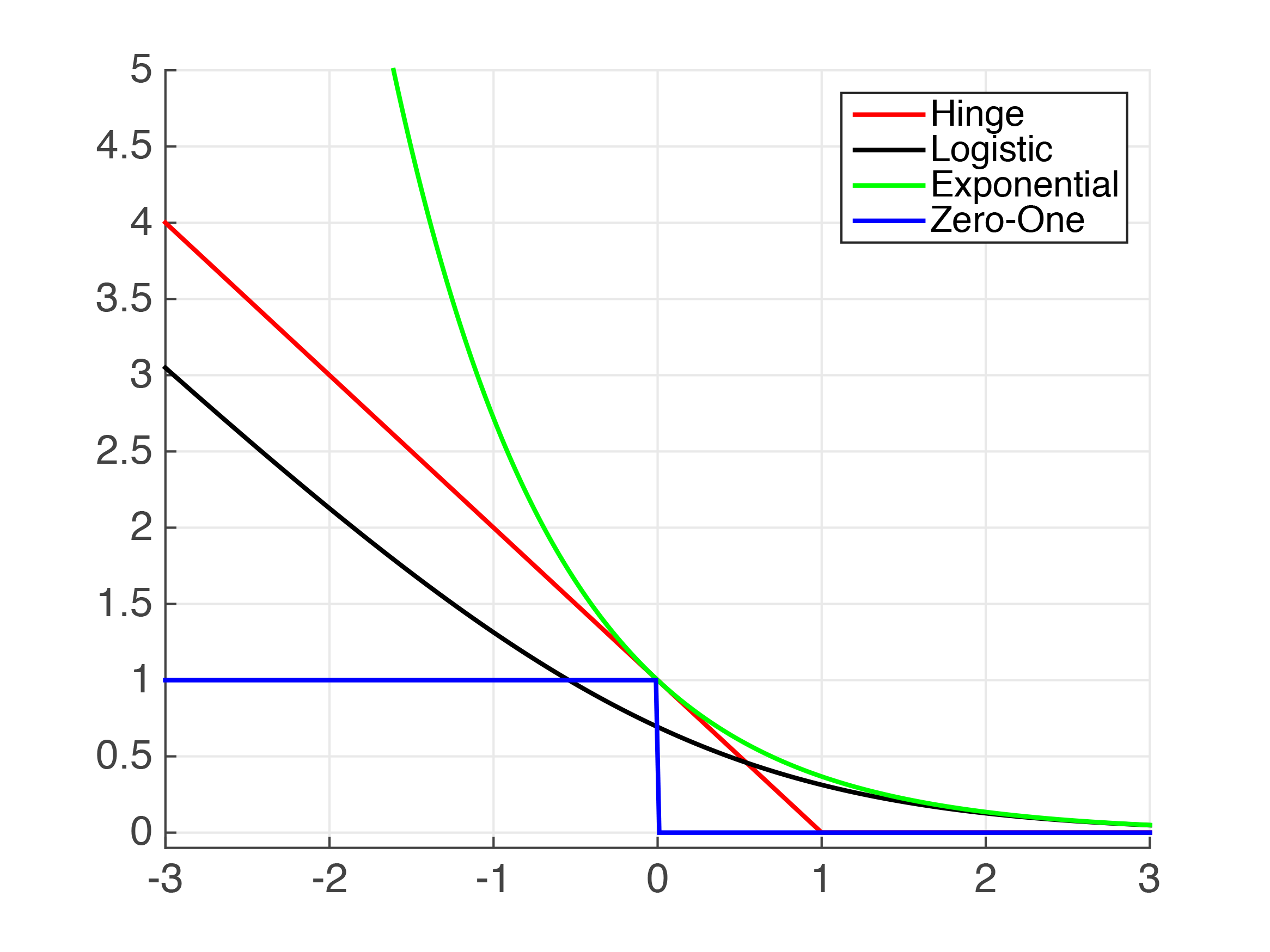
Understanding the 3 most common loss functions for Machine Learning Regression.
Exponential loss machine learning. For any particular loss function the empirical risk that we minimize is then Jθ 1 m Xm i1 ϕyiθTxi. AdaBoost can then be viewed as optimizing the exponential loss. About Press Copyright Contact us Creators Advertise Developers Terms Privacy Policy Safety How YouTube works Test new features Press Copyright Contact us Creators.
George Seif in Towards Data Science. The output of the other learning algorithms is combined into a weighted sum that represents the final output of the. It can be used in conjunction with many other types of learning algorithms to improve performance.
For the disadvantages of 01 loss exponential loss has the following two improvements. As in -11 case we often use exponential loss function for it and its formula should be like. For AdaBoost it solves this equation for the exponential loss function under the constraint that ϕmx only outputs -1 or 1.
R Rbe the loss functionthat is the loss for the example xy with margin z yxTθ is ϕz ϕyxTθ. This function is very aggressive. Advanced Machine Learning - Mohri page Convex Surrogates Let be a decreasing convex function upper bounding with differentiable.
L expxyeyfx 4 so that the full learning objective function given training data xiyiN i1 is E X i e1 2 yi PM. We define fx 1 2 P m αmfmx and rewrite the classifier as gx signfxthe factor of 12 has no effect on the classifier output. Lw 1 N N i 1logpyii 1 pi1 yi regPart while both p i and regPart should be function of w.
Exponential loss function This loss function is an approximation of the 01 loss function. U u u 1 u0. So lets check Google search trends that track interest.
Let z yxTθ denote the margin and let ϕ. The main technique we will learn how to apply is called Linear Programming. We will study several alternative loss functions for linear models such as the L1 absolute loss maximum absolute deviation MAD and the exponential loss for when you want your error to be positive-only or negative-only.
It turns out that the academic community has something really brewing. The loss of a mis-prediction increases exponentially with the value of -h_mathbfwmathbfx_iy_i. AdaBoost short for Adaptive Boosting is a statistical classification meta-algorithm formulated by Yoav Freund and Robert Schapire who won the 2003 Gödel Prize for their work.
Custom and Asymmetric Loss. We wish to have yiθTxi positive for each. 2 Consider our desired behavior.
Name a few. Log loss focal loss exponential loss hinge loss relative entropy loss and other. I Hinge loss less sensitive to outliers than exponential or logistic loss I Logistic loss has a natural probabilistic interpretation I We can optimize exponential loss e ciently in a greedy manner Adaboost Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 1 2017 6 32.
While GBM and XGBoost can be viewed as two general boosting algorithms that solve the equation approximately for any suitable loss function. And the formula should be like. One of the most popular loss functions in Machine Learning since its outputs are very well-tuned.
Lw log1 exp yi si regPart while both s. While more commonly used in regression the square loss function can be re-written and utilized for classification.

Ai What Is My Data Worth Ai Machinelearning Tech Gadgets A I Machine Learning Models Data Machine Learning

What Is The Difference Between Machine Learning And Deep Learning Artificial Intell Deep Learning Artificial Intelligence Algorithms Artificial Intelligence
What Are Different Loss Functions Used As Optimizers In Neural Networks Analytics Steps

Deep Learning Exponential Growth Trends Deep Learning Exponential Exponential Growth

Knee Of An Exponential Curve Exponential Growth Singularity Exponential

Uber Ai Labs Proposes Loss Change Allocation Lca A New Method That Provides A Rich Window Into The Neural Network Training Process Networking Loss Train
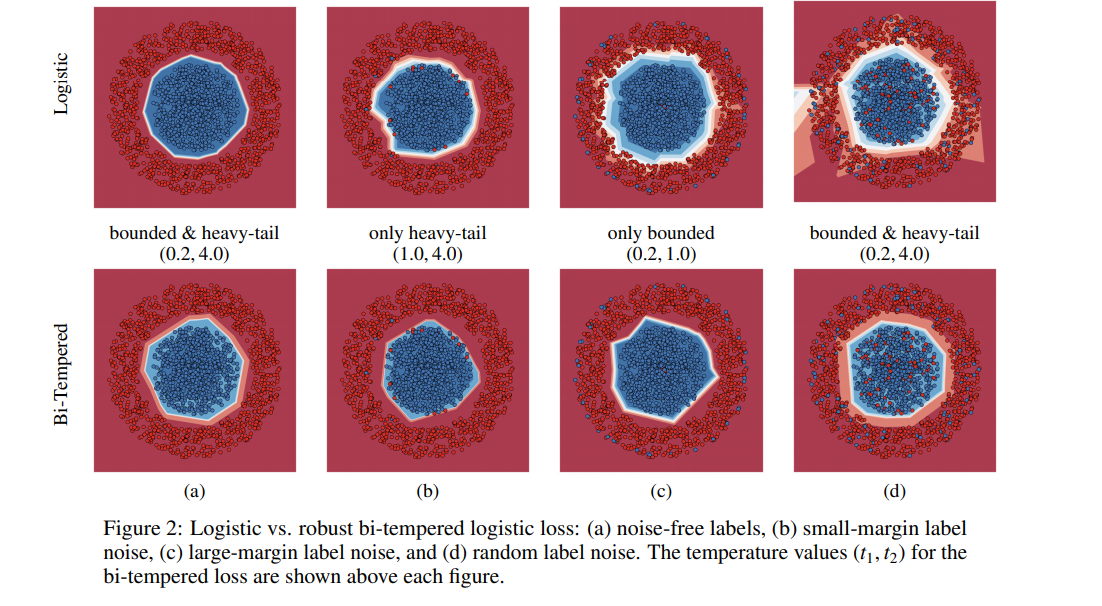
Research Guide Advanced Loss Functions For Machine Learning Models By Derrick Mwiti Heartbeat
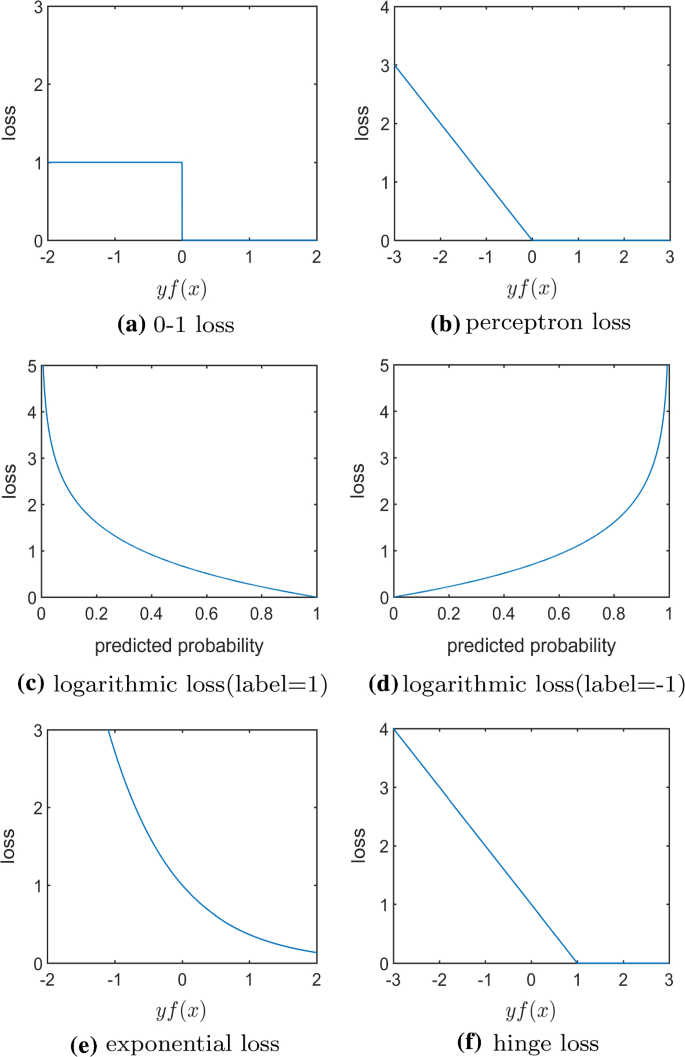
A Comprehensive Survey Of Loss Functions In Machine Learning Springerlink

Loss Functions For Classification Wikipedia Step Function Learning Theory Learning Problems
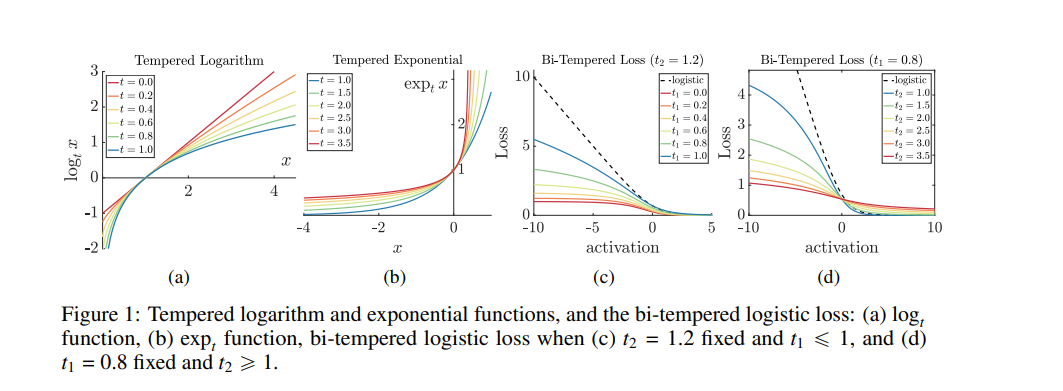
Research Guide Advanced Loss Functions For Machine Learning Models By Derrick Mwiti Heartbeat
Understanding Learning Rates And How It Improves Performance In Deep Learning By Hafidz Zulkifli Towards Data Science

Introduction To Loss Functions
Loss Function Loss Function In Machine Learning
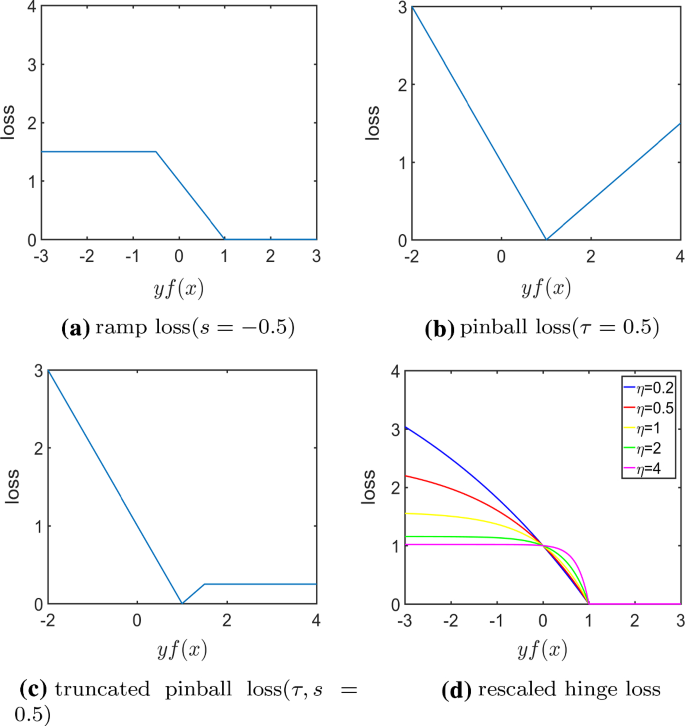
A Comprehensive Survey Of Loss Functions In Machine Learning Springerlink

The Unknown Benefits Of Using A Soft F1 Loss In Classification Systems Nlp System Machine Learning

Introduction To Loss Functions
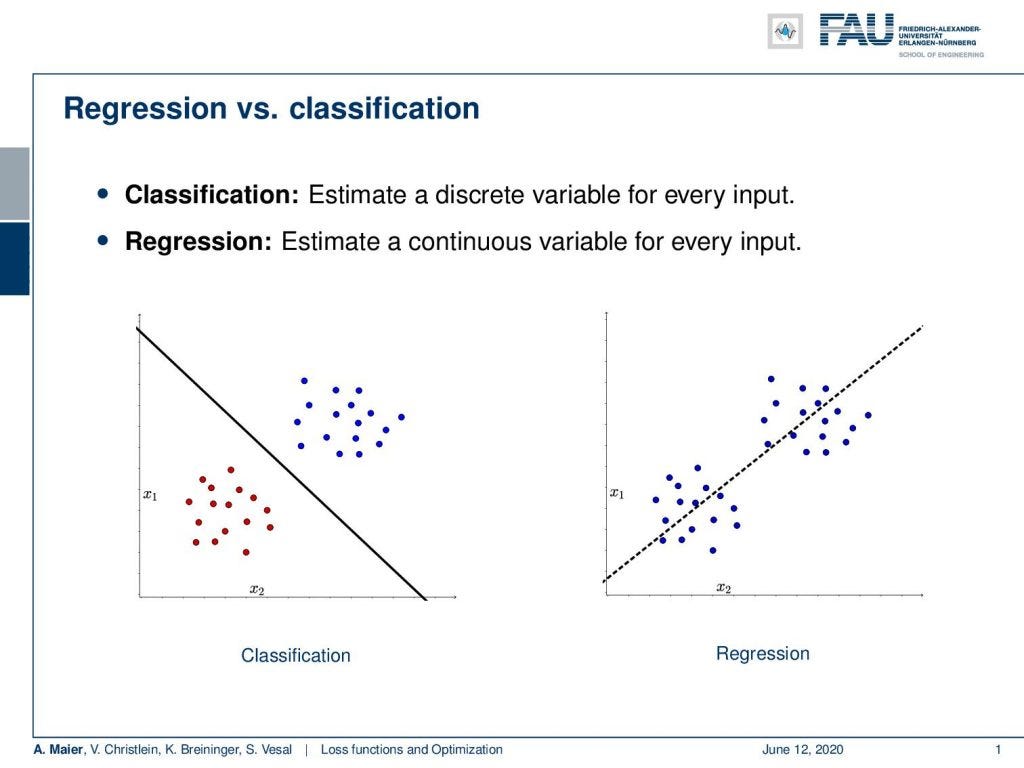
Loss And Optimization Part 1 Classification And Regression Losses By Andreas Maier Towards Data Science

Pin By Xfrita S On New Data Health Management Deep Learning Machine Learning

What Is Deep Learning What Are Its Benefits Computer History What Is Deep Learning History
Post a Comment for "Exponential Loss Machine Learning"