Hyperparameter Optimization Machine Learning Mastery
So by changing the values of the hyperparameters you can find different and hopefully bettermodels. Hyperparameters are different from parameters which are the internal coefficients or weights for a model found by the learning algorithm.
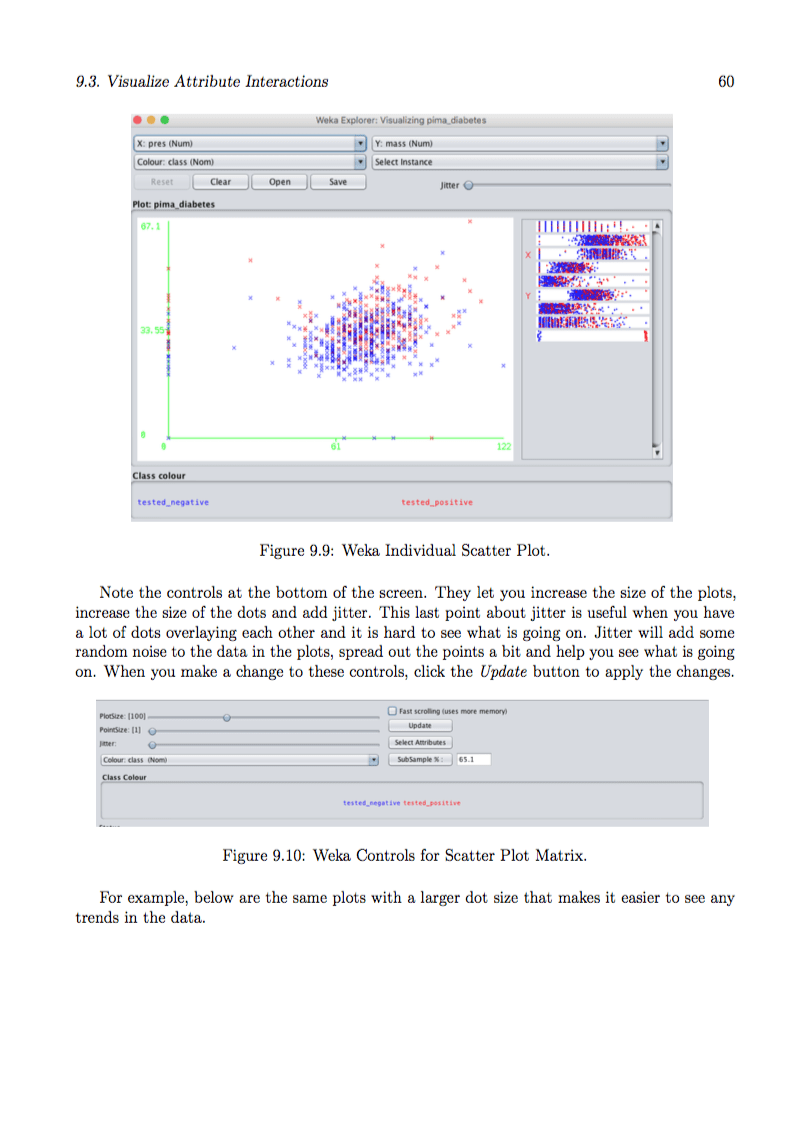
Machine Learning Mastery With Weka
Improve the reproducibility and fairness of scientic studies.

Hyperparameter optimization machine learning mastery. Hyperparameter optimization is a big part of deep learning. Hyperparameter Optimization With Random Search and Grid Search. There are many ways to perform hyperparameter optimization although modern methods such as Bayesian Optimization are fast and effective.
In short hyperparameters are different parameter values that are used to control the learning process and have a significant effect on the performance of machine learning models. Gradient descent is an optimization algorithm that follows the negative gradient of an objective function in order to locate the minimum of the function. Unlike parameters hyperparameters are specified by the practitioner when configuring the.
HYPERPARAMETER OPTIMIZATION improve the performance of machine learning algorithms by tailoring them to the problem at hand. Last Updated on August 28 2020. A limitation of gradient descent is that it uses the same step size learning rate for each input variable.
The parameters that control a machine learning algorithms behavior are called hyperparameters. AdaGrad for short is an extension of the gradient descent optimization algorithm that allows the step size in. The Wikipedia page gives the straightforward definition.
For example it is possible to use stochastic optimization algorithms. Common examples of Hyperparameters are learning rate optimizer type activation function dropout rate. Grid and random search are primitive optimization algorithms and it is possible to use any optimization we like to tune the performance of a machine learning algorithm.
Taking one step higher again the selection of training data data preparation and machine learning algorithms themselves is also a problem of function optimization. The final chapter summaries the role of hyperparameter optimization in automated machine learning and ends with a tutorial to create your own AutoML script. The trade-off between the best model performance and the most optimized optimization technique is a factor that influences someones choice.
You can think of Hyperparameters as configuration variables you set when running some software. Hyperparameter Optimization in Machine Learning creates an understanding of how these algorithms work and how you can use them in real-life data science problems. On top of that individual models can be very slow to train.
Machine learning algorithms have hyperparameters that allow you to tailor the behavior of the algorithm to your specific dataset. Optimization also refers to the process of finding the best set of hyperparameters that configure the training of a machine learning algorithm. This has led to new state-of-the-art per- formances for important machine learning benchmarks in several studies eg.
By contrast the value of other parameters is derived via training. Azure Machine Learning lets you automate hyperparameter tuning and run experiments in parallel to efficiently optimize hyperparameters. Depending on the values you select for your hyperparameters you might get a completely different model.
Hyperparameter optimization refers to performing a search in order to discover the set of specific model configuration arguments that result in the best performance of the model on a specific dataset. An example of hyperparameters in the Random Forest algorithm is the number of estimators n_estimators maximum depth max_depth and criterion. Hyperparameter Optimization in Machine Learning Models This tutorial covers what a parameter and a hyperparameter are in a machine learning model along with why it is vital in order to enhance your models performance.
Summary of optimization in machine learning. In the context of machine learning hyperparameters are parameters whose values are set prior to the commencement of the learning process. In this article we have covered 7 hyperparameter optimization techniques one can use to get the best set of hyperparameters leading to training a robust machine learning model.
The reason is that neural networks are notoriously difficult to configure and there are a lot of parameters that need to be set. Define the search space Tune hyperparameters by exploring the range of values defined for each hyperparameter. Hyperparameters are never learned but set by you or your algorithm and govern the whole training process.

Machine Learning Mastery With R
Https Www Imperial Ac Uk Media Imperial College Faculty Of Engineering Computing Public 1819 Ug Projects Matachec Efficient Design Of Machine Learning Hyperparameter Optimizers Pdf
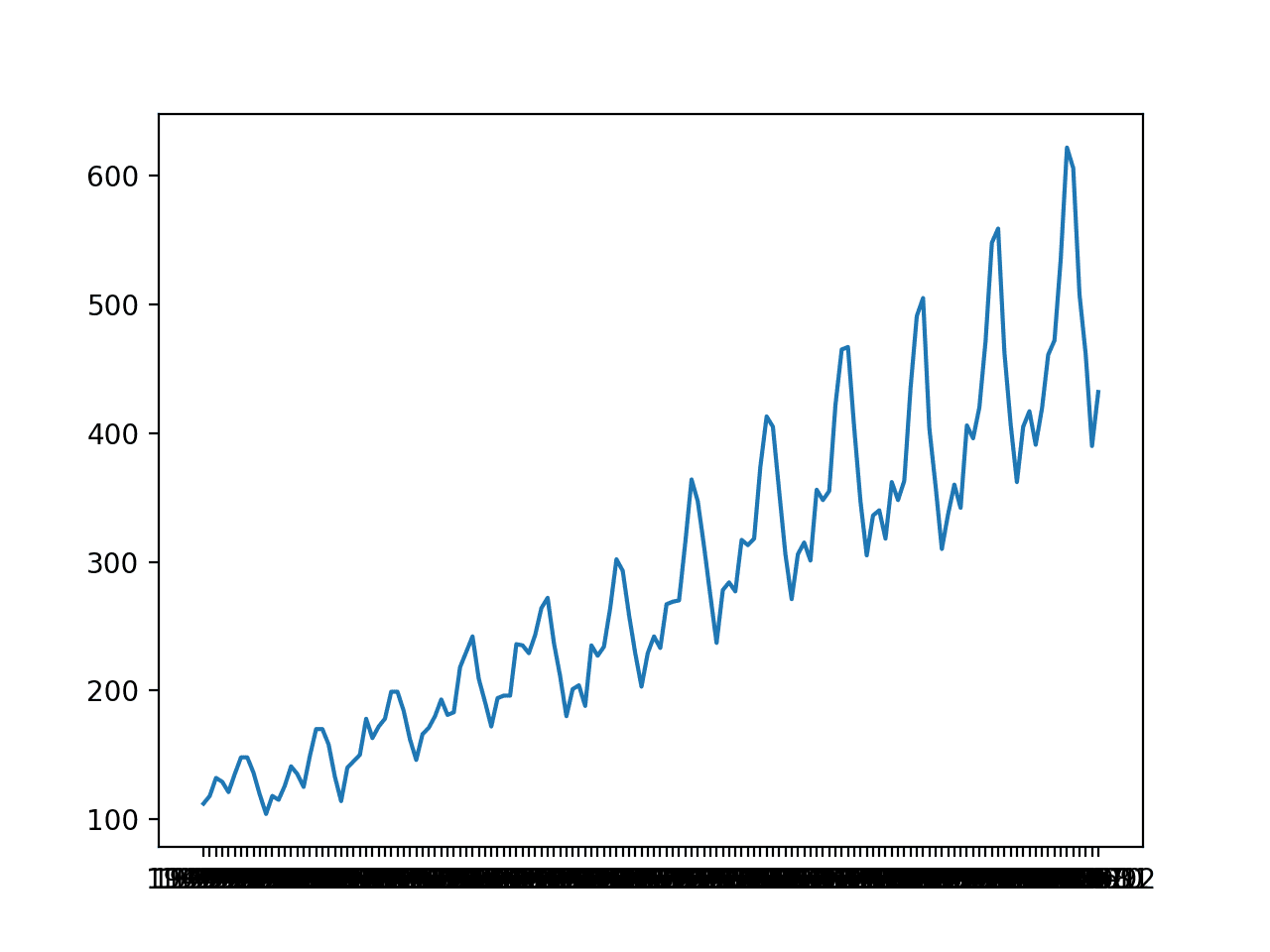
How To Grid Search Deep Learning Models For Time Series Forecasting
Machine Learning Mastery Jason Brownlee Statistical Methods For Machine Learning Scientific Theories Tests

Machine Learning Mastery With R

Machine Learning Mastery With Weka
![]()
Start Here With Machine Learning

Efficient Hyperparameter Optimization For Xgboost Model Using Optuna

Machine Learning Tutorial Decision Tree Hyperparameter Optimization Youtube

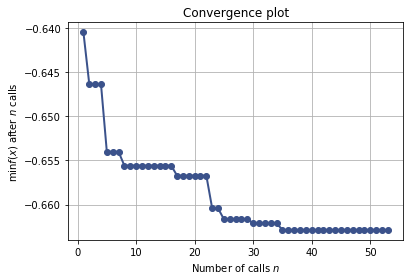
Scikit Optimize For Hyperparameter Tuning In Machine Learning Machine Learning Mastery
Learn To Learn Hyperparameter Tuning And Bayesian Optimization Ju Yang
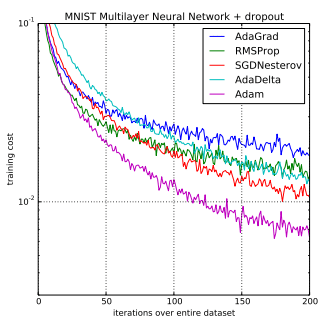
Gentle Introduction To The Adam Optimization Algorithm For Deep Learning

How To Grid Search Hyperparameters For Deep Learning Models In Python With Keras
2

Hacker S Guide To Hyperparameter Tuning Curiousily Hacker S Guide To Machine Learning

5 Powerful Ways To Master Hyperparameter Tuning
Efficient Hyperparameter Optimization For Xgboost Model Using Optuna

Hyperparameter Tuning In Machine Learning Grid Search How It Works And Sklearn Implementation Youtube
![]()
Machine Learning Mastery Workshop Virtual Course Enthought
Post a Comment for "Hyperparameter Optimization Machine Learning Mastery"