L1 Regularization Machine Learning Mastery
This type of regularization L1 can lead to zero coefficients ie. This is a form of regression that constrains regularizes or shrinks the coefficient estimates towards zero.
Regularization In Machine Learning And Deep Learning By Amod Kolwalkar Analytics Vidhya Medium
In this experiment we will compare L1 L2 and L1L2 with a default value of 001 against the baseline model.
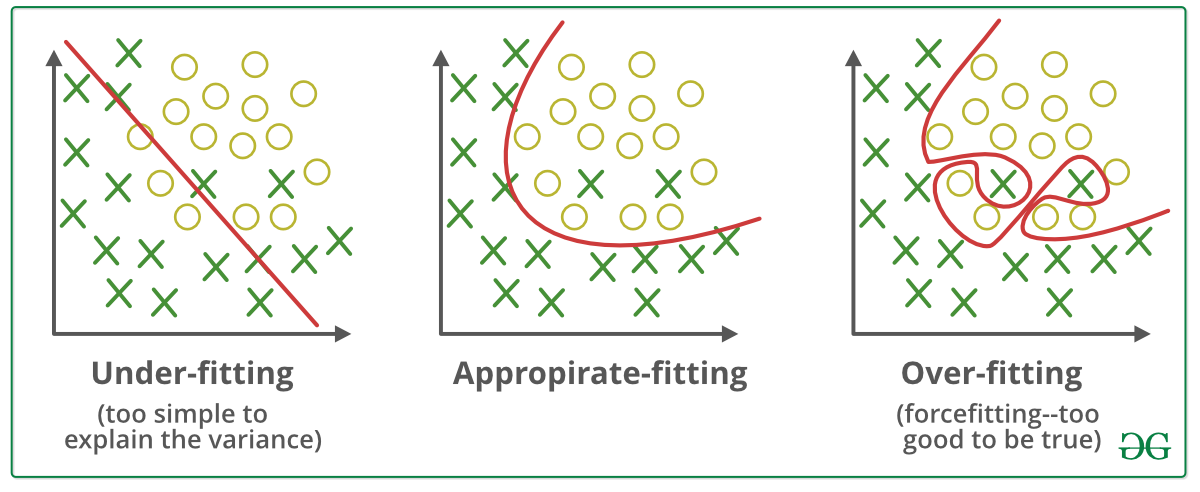
L1 regularization machine learning mastery. Weight regularization provides an approach to reduce the overfitting of a deep learning neural network model on the training data and improve the performance of the model on new data such as the holdout test set. In other words this technique discourages learning a more complex or flexible model so as to avoid the risk of overfitting. The basis of L1-regularization is a fairly simple idea.
The length of a vector can be calculated using the L2 norm where the 2 is a superscript of the L eg. This is also caused by the derivative. So Lasso regression not only helps in reducing over-fitting but it can help us in feature selection.
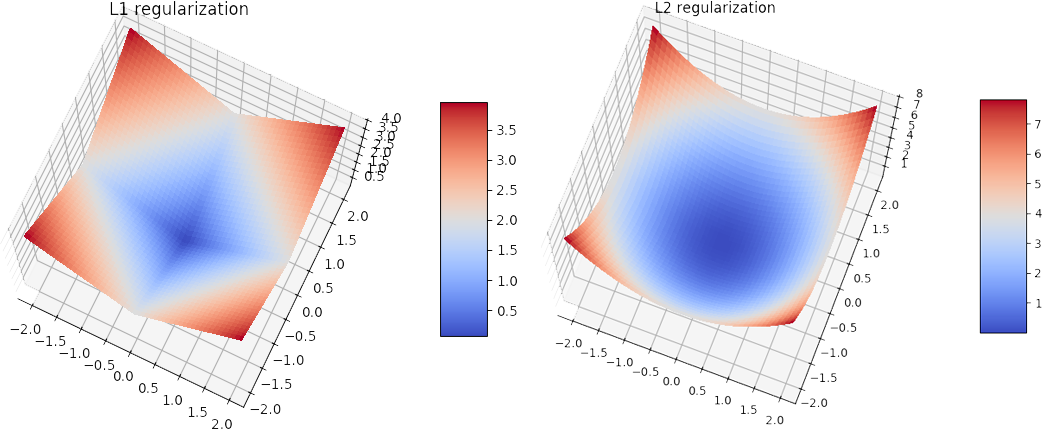
Mathematical Formula for L1 regularization. The key difference between these two is the penalty term. Regularization achieves this by introducing a penalizing term in the cost function which assigns a higher penalty to complex curves.
Some of the features are completely neglected for the evaluation of output. Just as in L2-regularization we use L2- normalization for the correction of weighting coefficients in L1-regularization we use special L1- normalization. We can specify all configurations using the L1L2 class as follows.
This is similar to applying L1 regularization. Even we obtain the computational advantage because features with zero coefficients can be avoided. A regression model that uses L1 regularization technique is called Lasso Regression and model which uses L2 is called Ridge Regression.
As in the case of L2-regularization we simply add a penalty to the initial cost function. The regularizer is defined as an instance of the one of the L1 L2 or L1L2 classes. Common values are on a logarithmic scale between 0 and 01 such as 01 0001 00001 etc.
Confusingly the alpha hyperparameter can be set via the l1_ratio argument that controls the contribution of the L1 and L2 penalties and the lambda hyperparameter can be set via the alpha argument that controls the. L1 regularization is the preferred choice when having a high number of features as it provides sparse solutions. There are multiple types of weight regularization such as L1 and L2 vector norms and each requires a hyperparameter that must be configured.
The L1 norm is often used when fitting machine learning algorithms as a regularization method eg. The regression model that uses L1 regularization technique is called Lasso Regression. Applying L2 regularization does lead to models where the weights will get relatively small values ie.
Where they are simple. There are essentially two types of regularization techniques- L1 Regularization or LASSO regression. Regularization is a concept by which machine learning algorithms can be prevented from overfitting a dataset.
In this python machine learning tutorial for beginners we will look into1 What is overfitting underfitting2 How to address overfitting using L1 and L2 re. What is L1 Regularization. Keras Usage of Regularizers.
Contrary to L1 where the derivative is a. Last Updated on August 25 2020. A hyperparameter must be specified that indicates the amount or degree that the loss function will weight or pay attention to the penalty.
A method to keep the coefficients of the model small and in turn the model less complex. The scikit-learn Python machine learning library provides an implementation of the Elastic Net penalized regression algorithm via the ElasticNet class. However contrary to L1 L2 regularization does not push your weights to be exactly zero.
Use of the L1 norm may be a more commonly used penalty for activation regularization. Ridge regression adds squared magnitude of coefficient as penalty term to the loss function. A simple relation for linear regression looks like this.
Weight Regularization With Lstm Networks For Time Series Forecasting
Regularization In Machine Learning And Deep Learning By Amod Kolwalkar Analytics Vidhya Medium

Regularization In Machine Learning And Deep Learning By Amod Kolwalkar Analytics Vidhya Medium
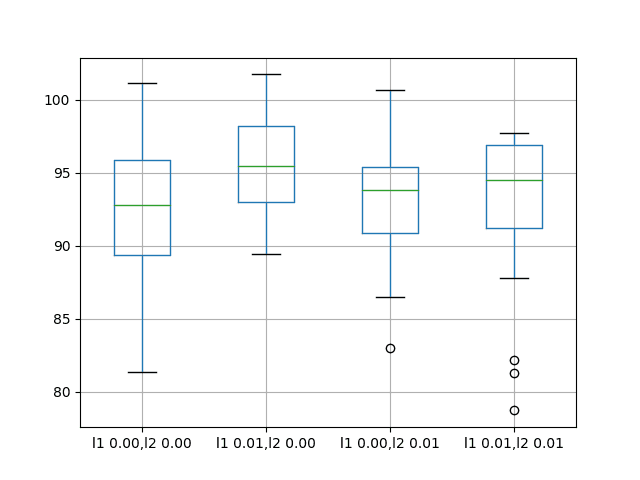
Weight Regularization With Lstm Networks For Time Series Forecasting
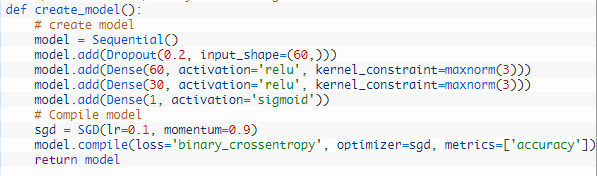
Regularisation Techniques In Machine Learning And Deep Learning By Saurabh Singh Analytics Vidhya Medium

Logistic Regression Tutorial For Machine Learning

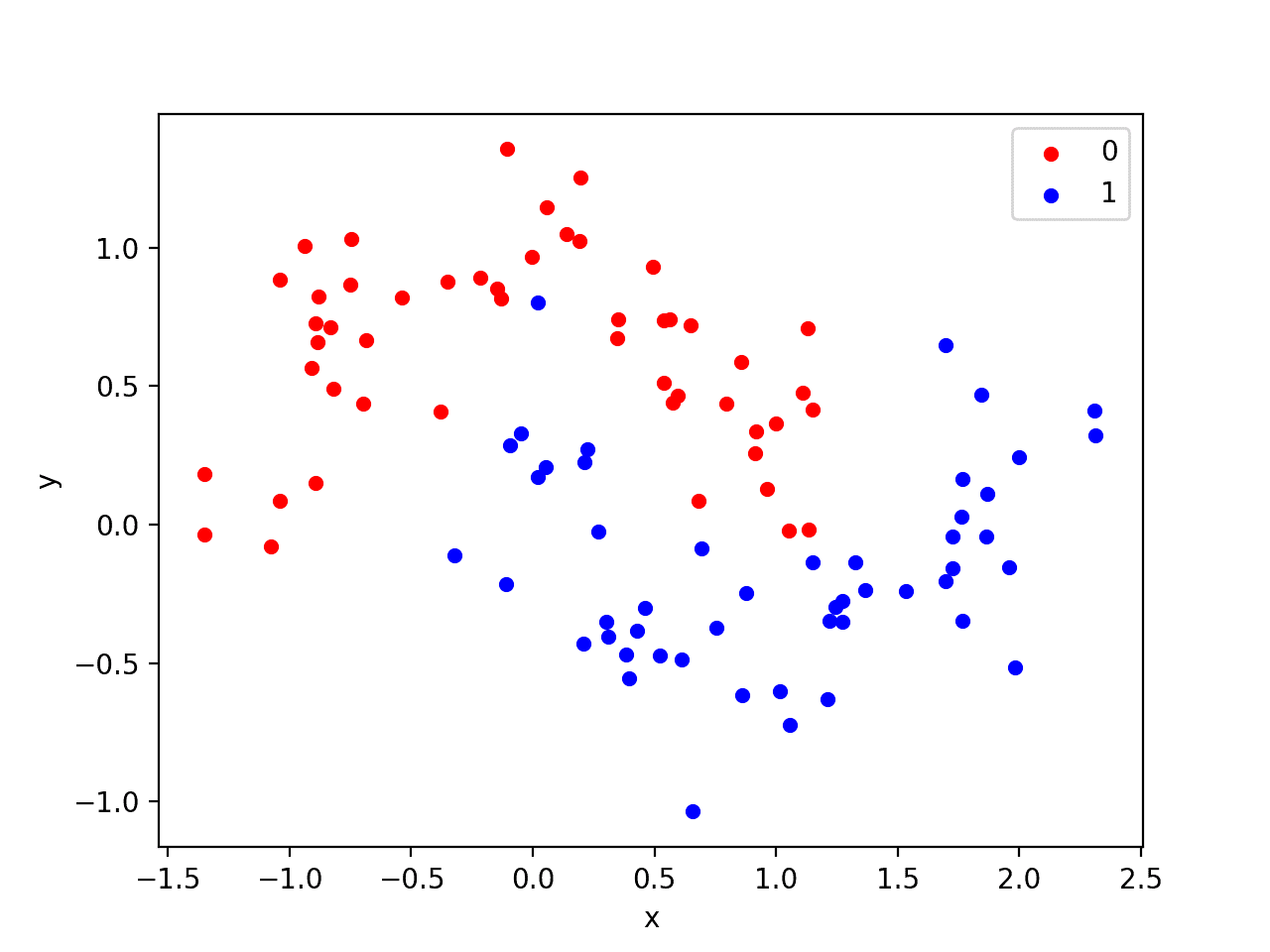
Weight Regularization Provides An Approach To Reduce The Overfitting Of A Deep Learning Neural Network Model On The Deep Learning Machine Learning Scatter Plot

What Are L1 L2 And Elastic Net Regularization In Neural Networks Machinecurve

What Are L1 L2 And Elastic Net Regularization In Neural Networks Machinecurve
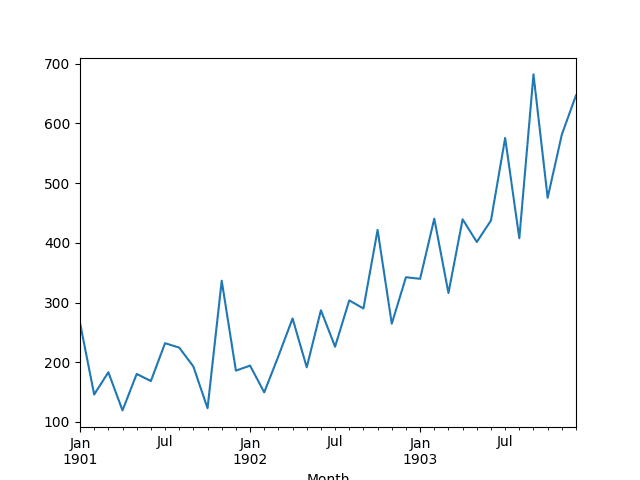
Weight Regularization With Lstm Networks For Time Series Forecasting

What Is Regularization In Machine Learning
Regularization Four Techniques Problem Solving By Mia Morton Medium
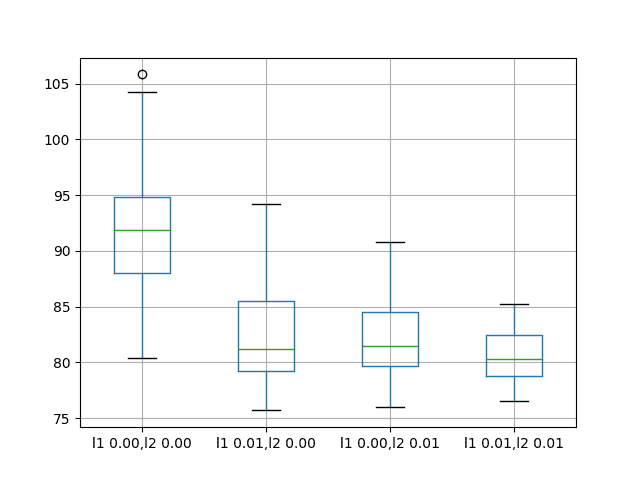
Weight Regularization With Lstm Networks For Time Series Forecasting
![]()
Machine Learning Mastery Workshop Virtual Course Enthought
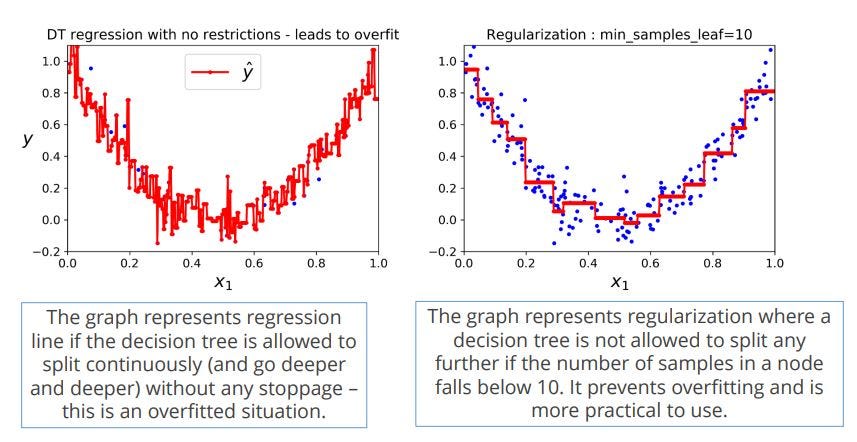
Regularization Four Techniques Problem Solving By Mia Morton Medium
Regularization In Machine Learning And Deep Learning By Amod Kolwalkar Analytics Vidhya Medium

Pin On Data Science Scoop It
How To Reduce Overfitting Of A Deep Learning Model With Weight Regularization Signal Surgeon
![]()
A Gentle Introduction To The Gradient Boosting Algorithm For Machine Learning
Post a Comment for "L1 Regularization Machine Learning Mastery"