Machine Learning Regularization Meaning
It is a technique to prevent the model from overfitting by adding extra information to it. Simple model will be a very poor generalization of data.

Machine Learning Algorithms In Layman S Terms Part 1 By Audrey Lorberfeld Towards Data Science
Overfitting is a phenomenon that occurs when a Machine Learning model is constraint to training set and not able to perform well on unseen data.

Machine learning regularization meaning. At the same time complex model may not perform well in test data due to over fitting. Regularization is one of the most important concepts of machine learning. Regularization is a concept by which machine learning algorithms can be prevented from overfitting a dataset.
Regularisation is a technique used to reduce the errors by fitting the function appropriately on the given training set and avoid overfitting. We need to choose the right model in between simple and complex model. Regularization is a technique used to avoid this overfitting problem.
It is also considered a process of adding more information to resolve a complex issue and avoid over-fitting. In order to create less complex parsimonious model when you have a large number of features in your dataset some. In other terms regularization means the discouragement of learning a more complex or more flexible machine learning model to prevent overfitting.
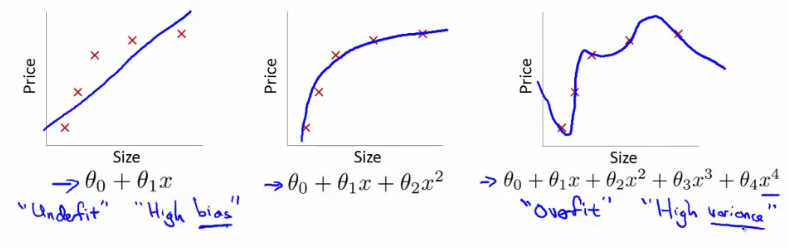
How Does Regularization Work. The idea behind regularization is that models that overfit the data are complex models that have for example too many parameters. In the example below we see how three different models fit the same dataset.
This is a form of regression that constrains regularizes or shrinks the coefficient estimates towards zero. In this post lets go over some of the regularization techniques widely used and the key difference between those. It means the model is not able to predict the output when deals with.
In the context of machine learning regularization is the process. Regularization in Machine Learning What is Regularization. Regularization can be implemented in multiple ways by either modifying the loss function sampling method or the training approach itself.
It is one of the most important concepts of machine learning. In general regularization means to make things regular or acceptable. So to deal with the problem of overfitting we take the help of regularization techniques.
Regularization can be applied to objective functions in ill-posed optimization problems. In my last post I covered the introduction to Regularization in supervised learning models. Regularization achieves this by introducing a penalizing term in the cost function which assigns a higher penalty to complex curves.
In machine learning regularization is a procedure that shrinks the co-efficient towards zero. Sometimes the machine learning model performs well with the training data but does not perform well with the test data. In the context of machine learning regularization is the process which regularizes or shrinks the coefficients towards zero.
The cheat sheet below summarizes different regularization methods. In simple words regularization discourages learning a more complex or flexible model to prevent overfitting. In mathematics statistics finance computer science particularly in machine learning and inverse problems regularization is the process of adding information in order to solve an ill-posed problem or to prevent overfitting.
Moving on with this article on Regularization in Machine Learning. This is exactly why we use it for applied machine learning. The regularization term or penalty imposes a cost on the optimization function to make the optimal.
Regularization is used in machine learning as a solution to overfitting by reducing the variance of the ML model under consideration. In other words this technique discourages learning a more complex or flexible model so as to avoid the risk of overfitting. There are essentially two types of regularization techniques-L1 Regularization or LASSO regression.
By noise we mean those data points in the dataset which dont really represent the true properties of your data but only due to a random chance. Regularization helps to solve over fitting problem in machine learning.

New Ai Approach Bridges The Slim Data Gap That Can Stymie Deep Learning Approaches Ein News Deep Learning Learning Projects Learning
Regularization In Deep Learning Deep Learning Has Found Great Success By Dharti Dhami Medium

Pin On Data Science

Pin On Data Science
4 The Overfitting Iceberg Machine Learning Blog Ml Cmu Carnegie Mellon University

Underfitting And Overfitting In Machine Learning
Regularization In Machine Learning Regularization In Java Edureka


Crash Blossom Machine Learning Glossary Data Science Machine Learning Methods Machine Learning
Regularization In Machine Learning Regularization In Java Edureka
What Is Regularization In Machine Learning Quora

A Simple Explanation Of Regularization In Machine Learning Nintyzeros

Machine Learning On Graphs A Model And Comprehensive Taxonomy Deepai Learning Methods Graphing Machine Learning

What Is Regularization In Machine Learning Quora
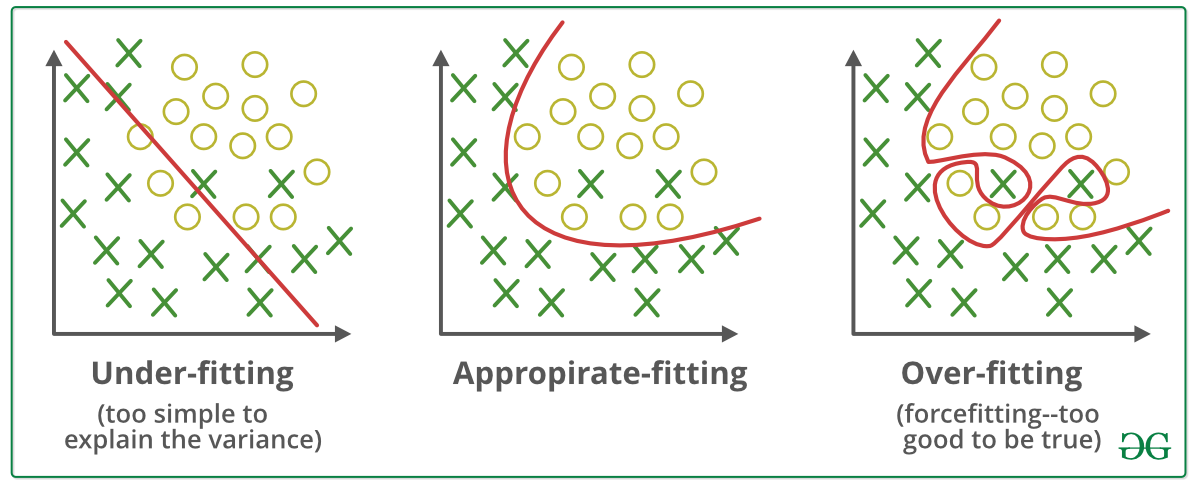
Regularization In Machine Learning Geeksforgeeks

Regularization In Machine Learning Data Science Interview Questions And Answers This Or That Questions

What Is Regularization In Machine Learning
What Is Machine Learning Regularization For Dummies By Rohit Madan Analytics Vidhya Medium

Pin By Satish N On Data Science Data Science Infographic Machine Learning Deep Learning
Improving Deep Neural Networks Hyperparameter Tuning Regularization And Optimization Neuralnetworks In 2020 Deep Learning Learning Courses Machine Learning Course
Post a Comment for "Machine Learning Regularization Meaning"